 Posted by
Posted by Our research mission is to bring the best intelligent autonomy to manufacturing. Undoubtedly, AI-driven industrial control is a big part of it. At NeurIPS 2021 (the most prestigious AI conference), we took part in a competition with two tracks on industrial control (one for open-loop control and one for closed-loop control).
And we won second place for both tracks! In fact, we achieved the best scores with pure Machine Learning techniques (which we believe should be more generalizable and scalable for more complex industrial processes in real life)!
Since everything can be found in this GitHub repository, we would like to just give a high-level summary of our winning approaches here.
Track CHEM (Open Loop Control)
The goal of this track is to find optimal controls on the concentrations of chemical compounds to ensure a specific target concentration on one of the products. A set of controls depending only on observed initial concentrations of the observed species must be selected for an optimal output when it is near a stable state.
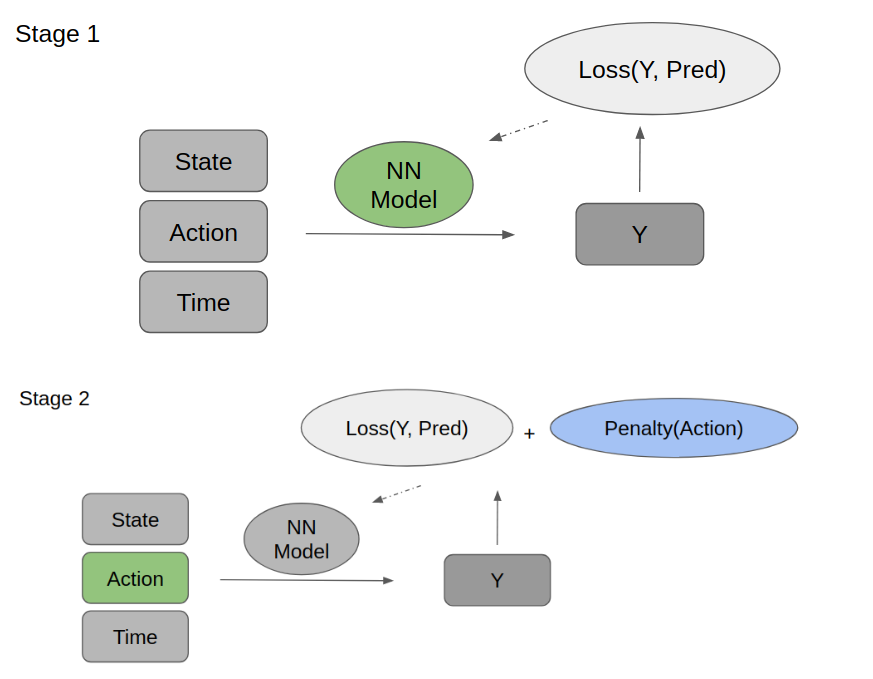
Our approach consists of 2 modeling stages. At stage 1, we predict the target with the initial state, action, and a future time step. The goal is to have a machine learning-based system dynamics estimation. And with that, we can find the optimal actions by optimizing the weighted loss of prediction errors and action penalties at stage 2.
More precisely, at stage 1, since we are just training on offline data, we update the neural network model from the error of the predicted target and actual target. And the model is then fixed at stage 2, while the actions are initialized randomly and get updated with an additional penalty as part of the loss.
Track ROBO (Closed Loop Control)
As stated in the whitepaper, this track is motivated by the challenge of learning skills that can be performed by a diverse set of robots. Robots will often have different dynamics and will be operating in a variety of environments when acquiring a new skill.
So it is essential for robots to use their own prior movement data to compute the skill controller for the new task.
Specifically, this track comes with two layers of difficulty:
1) Instead of directly controlling the robot (e.g., via setting the torques of individual joints) participants can only set abstracted control variables. This should imitate a setting in which the robot dynamics are too complicated to explicitly write down.
2) The training data is comprised of different types of trajectories than the later target trajectories. This imitates a setting in which the robot needs to adjust to a new task given the previous data of an old task. In addition, to mimic a real-time robot control scenario, the participants’ computational resources for updating their controller (or policy), are restricted.
While in practice, the best gains may come from more data collection, we need to develop a very sample-efficient model while making sure it doesn’t overfit offline and can run quickly online, for this challenge.
Namely, carefully engineered features and well-designed model components (e.g. custom loss, ensemble, action standardization, …) are the keys to our winning solution.
The full code for our solutions can be found here. And feel free to reach out if you would like to chat further!
