
Data Engineering Complexity: Significant effort is needed to prepare industrial data for processing.
IT-OT Divide: Enterprise tech stacks don’t align with OT protocols like OPC UA and MQTT.
Real-time Integration: Integrating asynchronous data in real-time is highly complex.
Incomplete Solutions: Existing solutions require custom coding, hindering scalability.
Quartic’s DataOps bridges the gap between IT and OT, creating an analytics-ready, event-driven data pipeline with standardized models for equipment, product, and process. This enables seamless data consumption at both the edge and the cloud, integrating IT technologies on the shop floor and delivering operational insights to enterprise teams.
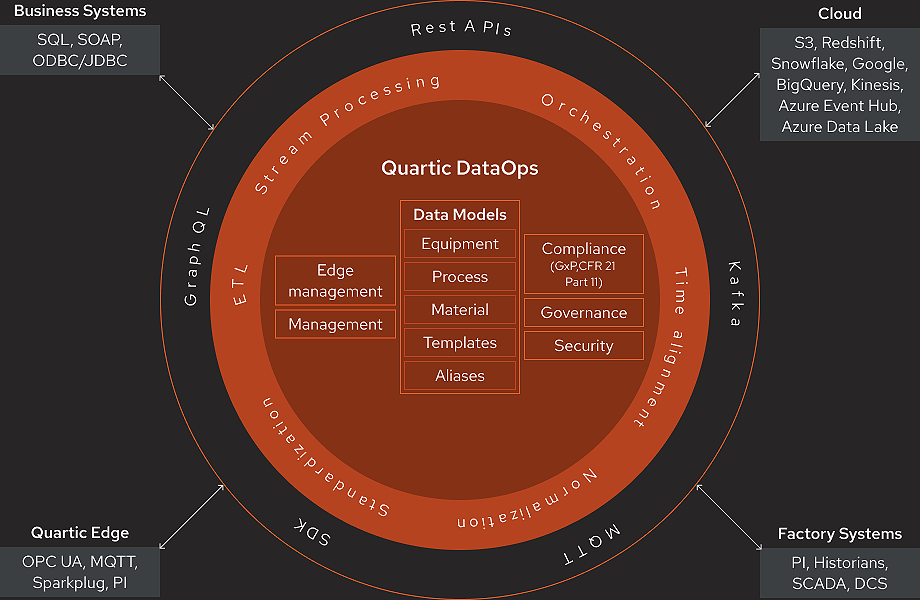
Quartic DataOps simplifies data integration and processing by combining MQTT’s simplicity at the edge and the distributed storage and processing of Kafka, with a purpose-built context engine. This results in a high-throughput, low-latency streaming data pipeline ready for real-time analytics.

Leverage ISA95/88 or custom industrial schemas to crowd-source context.

Share processed data through Kafka or GraphQL for broad application support.

Use existing enterprise infrastructure to build scalable industrial applications.
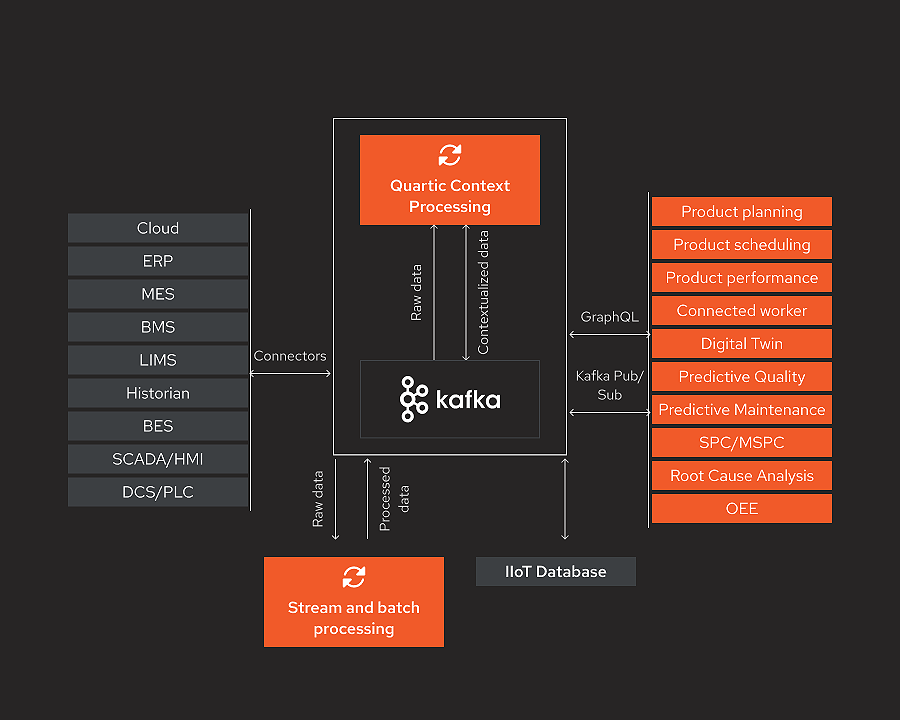
By leveraging Kafka for large-scale data operations, Quartic DataOps ensures data consistency, scalability, and fault tolerance. It seamlessly integrates time-series OT and MES data with transactional business systems data, creating enterprise-grade system-oriented data streams.
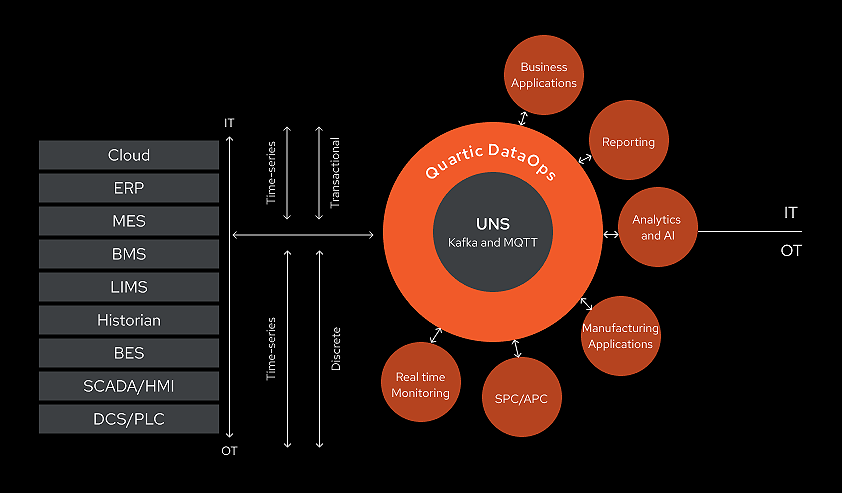
Quartic DataOps publish-subscribe architecture combines MQTT’s lightweight device connectivity and the event-driven processing power of Kafka, creating a unified namespace for seamless data integration across industrial applications. It also integrates legacy OPC-UA with Kafka and supports CDC for business systems, unifying manufacturing and enterprise data with a common context.
Unlike traditional IoT, Data Hub, and ETL systems that require custom coding, Quartic DataOps offers-
No-Code, Bi-Directional OT Connectivity: OPC-UA, MQTT Sparkplug B, Aveva PI historian, DeltaV Batch, Wonderware Batch, and SQL.
Cloud data Connectivity: S3, Redshift, Snowflake, and Google BigQuery.
Flexible Data Modeling: ISA95, ISA88, and user-defined schemas.
Event-Driven Data Processing: Powered by Kafka and Spark.
Scalable and Fault-Tolerant: Designed for scale and high availability.
Quartic DataOps enables a decentralized, domain-oriented data architecture, aligning with data mesh principles. It empowers teams to treat data as a product, creating self-service pipelines that keep your organization ahead of industry trends.
Join industry leaders who have successfully implemented Quartic DataOps. Take the next step toward a more efficient, scalable data management solution.